计算机组成原理 复习笔记
Ch.1 Intro
- 区分 CPI 和 MIPS 计算
- CPI: cycles per instructions
- MIPS: million instructions per second
- 几个概念区分:响应时间、性价比、吞吐率
- Amdahl 定律
假设原来在一个系统中执行一个程序需要时间
,其中某一个部分占的时间百分比为 ,然后,把这一部分的性能提升 倍。即这一部分原来需要的时间为 ,现在需要的时间变为 。则整个系统执行此程序需要的时间变为: 故可得,系统性能提速的倍数为:
Ch.2 Machine Level Representation of Data
- 补码 two's complement
- IEEE 754 浮点数标准 - 32 位单精度 float | 64 位双精度 double
- (规格化)浮点数的表示范围
- 特殊的浮点数
- 大小端排列 big / little endian
- 数据校验
- 校验基本原理
- 校验位 | 故障字
- 码距:各码字间的最小距离
- d=1,3 - 发现 d-1 位错,纠正 (d-1)/2 位错
- d=2,4 - 发现 d/2 位错,纠正 d/2-1 位错
- 奇偶校验码
- 码距 d=2
- 只能发现奇数位错误(一字节通常错一位)
- ❗ 海明码 Hamming code
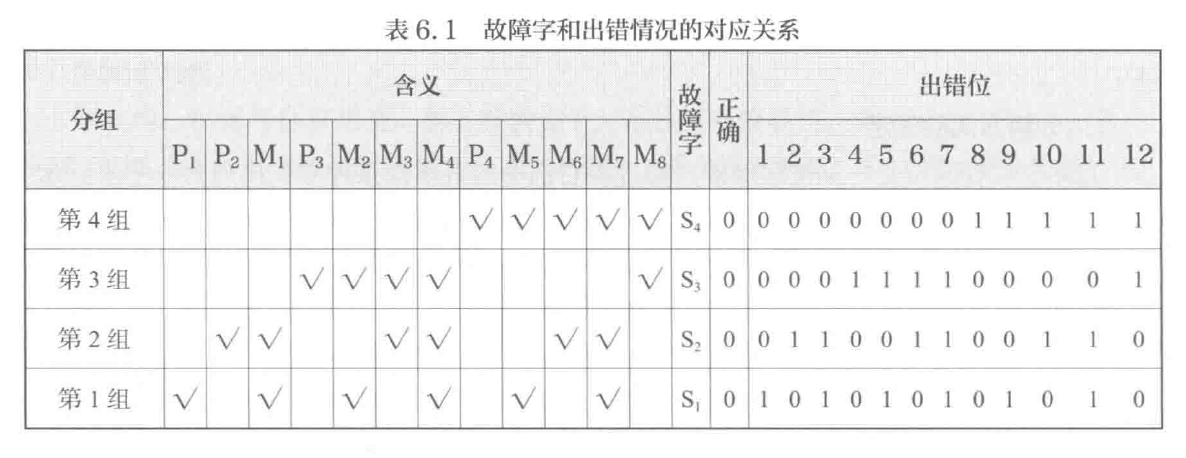
- n 位数据,k 位校验位:
- 码距 d=3(每个数据位至少参与两组奇偶效验位生成)
- “纠一检二”码 SEC-DED
- 码距 d=4(增加一位校验位,使每个数据位参与三个校验位生成)
- 校验基本原理
Ch.3 Data Operation
- 补码溢出
- 零标志 ZF - zero
- 符号标志 SF - sign
- 溢出标志 OF - overflow(带符号有效)
- 进位 / 借位 CF - carry (无符号有效)
- 浮点数运算舍入
- 对阶 2. 尾数加减 3. 尾数规格化 4. 尾数舍入
- 保护位 guard | 舍入位 round | 粘位 sticky
Ch.4 Instruction Set
- 寄存器传送语言 RTL
- 带符号扩展 / 零扩展 SEXT / ZEXT - sign / zero extension
- 6 种指令格式 R | I | S | B | U | J

- 过程调用约定
- 调用过程 P / 被调用过程 Q caller P / callee Q
- P 存放入口参数和返回地址
- Q 存放返回结果(以及非静态局部变量)
- ❗ 寄存器使用约定
- x0 (zero) - 硬编码 0
- x1 (ra) - 返回地址
- x2 (sp) - 栈指针
- x10~x11 (a0~a1) 入口参数 / 返回值
- x12~x17 (a2~a7) 入口参数
- x8 (s0/fp) 保存寄存器 / 帧指针
- x9 (s1) 保存寄存器
- x18~x27 (s2~s11) 保存寄存器(保存到栈)
- (t0~t6) 临时寄存器
- 每个过程有自己的栈区——栈帧 stack frame
- 用户栈的状态变化示例
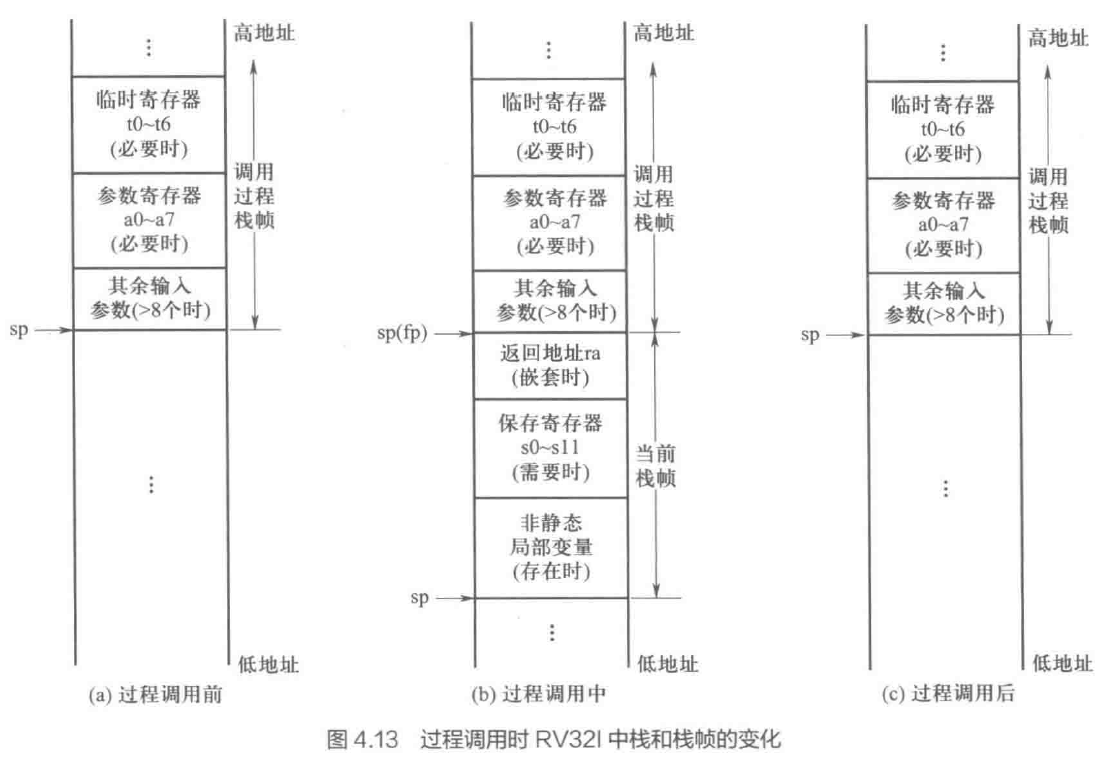
- 调用过程 P / 被调用过程 Q caller P / callee Q
Ch.5 CPU Design
- 流水线处理器
- 插入“空”功能段对齐流水线
- 提高的是整个程序指令执行的吞吐率,而非单条指令执行速度
- ❗ 流水线冒险
- 结构冒险 structural hazards - 同一部件被不同指令同时使用
- 寄存器访问冲突:独立读口 / 写口 Rwr / Rrd
- 存储器访问冲突:拆分指令存储器 / 数据存储器 IM / DM
- 数据冒险 data hazards - 后面的指令要用前面指令的结构
- 写后读数据冒险 read after write, RAW
- 插入空操作指令
- 插入气泡
- 转发技术 - 中间数直接传给后面的指令
- 特例:Load-use 数据冒险
- 在 lw 指令后跟 R / I 型运算类指令
- 只能编译优化 / 插入 nop
- 写后读数据冒险 read after write, RAW
- 控制冒险 control hazards - 由分支指令引起的流水线阻塞
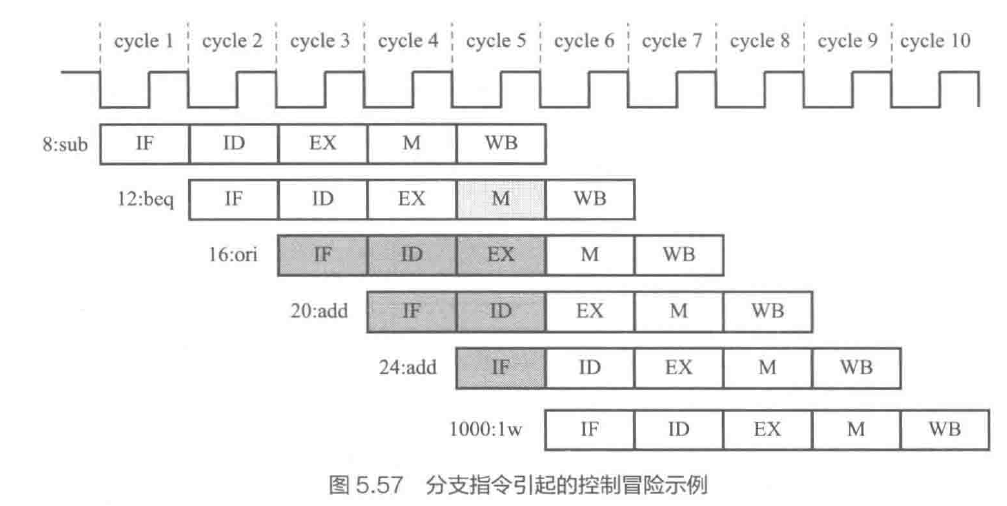
- 延迟损失时间片 C
- 简单预测(总是不转移)/ 动态预测
- 流水线周期图分析
- 出现 Load-use 数据冒险,下一条流水线延后两周期(额外阻塞一周期)
- stall=1(ID/EX 寄存器所有控制信号清零)
- IF/ID.write=0(暂停 IF/ID 寄存器写,Load后一指令继续保存)
- PCwrite=0(PC值不更新)
- 若采用静态预测,出现控制冒险,下一条流水线延后一周期
- PCwrite=1(更新PC)
- IF/ID.flush=1(清除预取的错误指令)
- ID/EX.flush=1(同上)
- 出现 Load-use 数据冒险,下一条流水线延后两周期(额外阻塞一周期)
- 结构冒险 structural hazards - 同一部件被不同指令同时使用
Ch.6 Memory
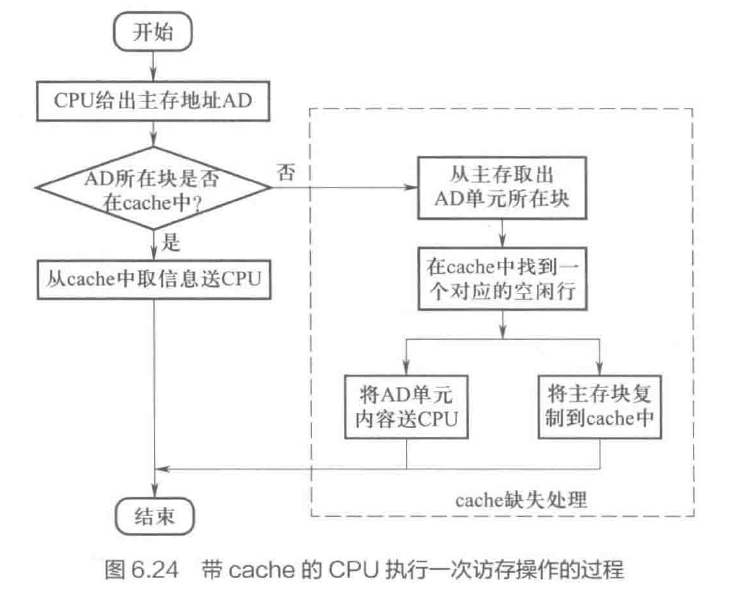
- 高速缓存 cache
- 局部性原理
- 信息交换单位——主存块 / cache 行
- cache 有效位,确认信息是否有效
- cache 对程序员是透明的
- 块映射到 cache 行
- 直接映射 主存块与 cache 行“多对一”严格对应
- cache 行号 = 主存块号 mod cache 行数
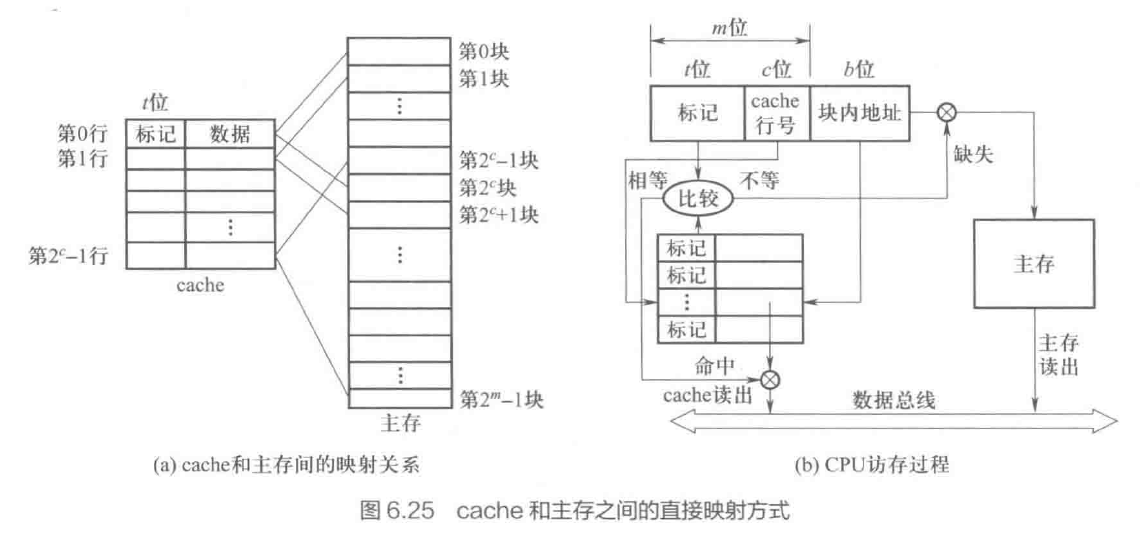
- 若 cache
行,主存 块,则取 位主存块号中后 位作为 cache 行号 - 标记 tag
- 长度
- 即块号高
位设置为标记
- 长度
- cache 行号 = 主存块号 mod cache 行数
- 全相联映射 块可装入任意 cache 行,无行索引
- 组相联映射 cache 行被划分为
组,组间直接映射,组内全映射 - cache 组号 = 主存块号 mod cache 组数
- 关联度 vs. 命中率 | 命中时间 | 标记所占额外开销
- 直接映射 主存块与 cache 行“多对一”严格对应
- 块的替换算法
- 先进先出 FIFO(缺失率高)
- 最近最少使用 LRU
- 计数器(LRU 位)记录主存块的使用情况
- 可能出现抖动 thrashing
- cache 一致性问题(写操作)
- 通写法 write through “同步更新”
- 回写法 write back “异步更新”(即某行中的主存块被替换时再写回主存)
- 需设置修改位 dirty bit
- =0 未修改过,无需写回
- =1 修改过,需写回
- 需设置修改位 dirty bit
- 虚拟地址空间
- 每个进程有独立的虚拟地址空间
- 主存作为外存的缓存
- 交换单位为页 virtual page, VP
- 全相联映射,以提高命中率(缺页处理慢)
- 回写法(外存访问慢
- 页表描述虚拟页对应的主存页框号 / 磁盘存储位置
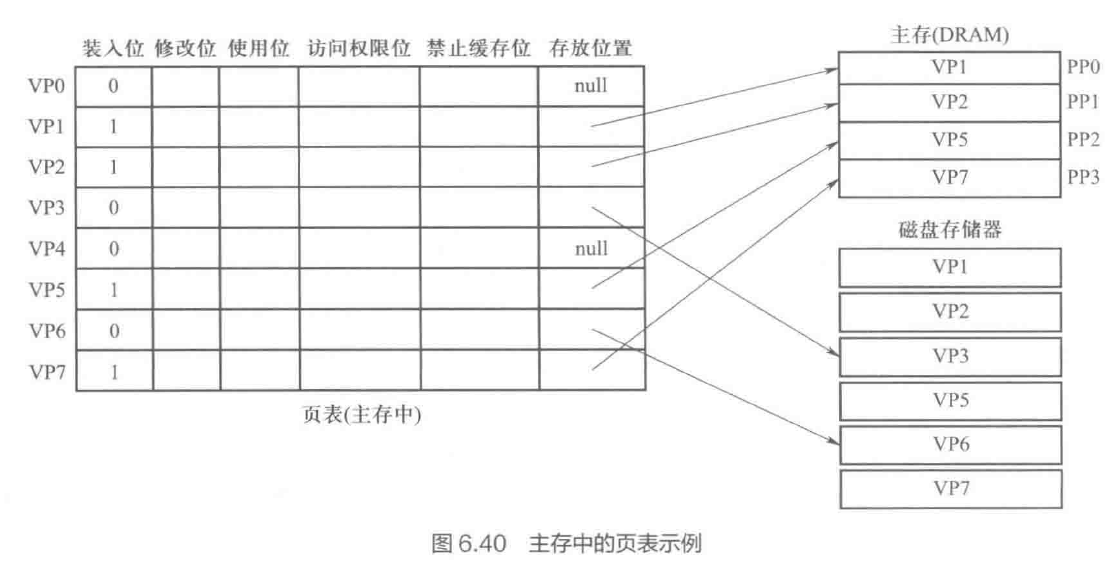
- 快表 TLB
- 保存在高速缓存中
- TLB 标记字段 + 页表项内容(tag 原理同 cache)
- TLB 满,通常采用随机替换
- 一个典型的 CPU 访存过程
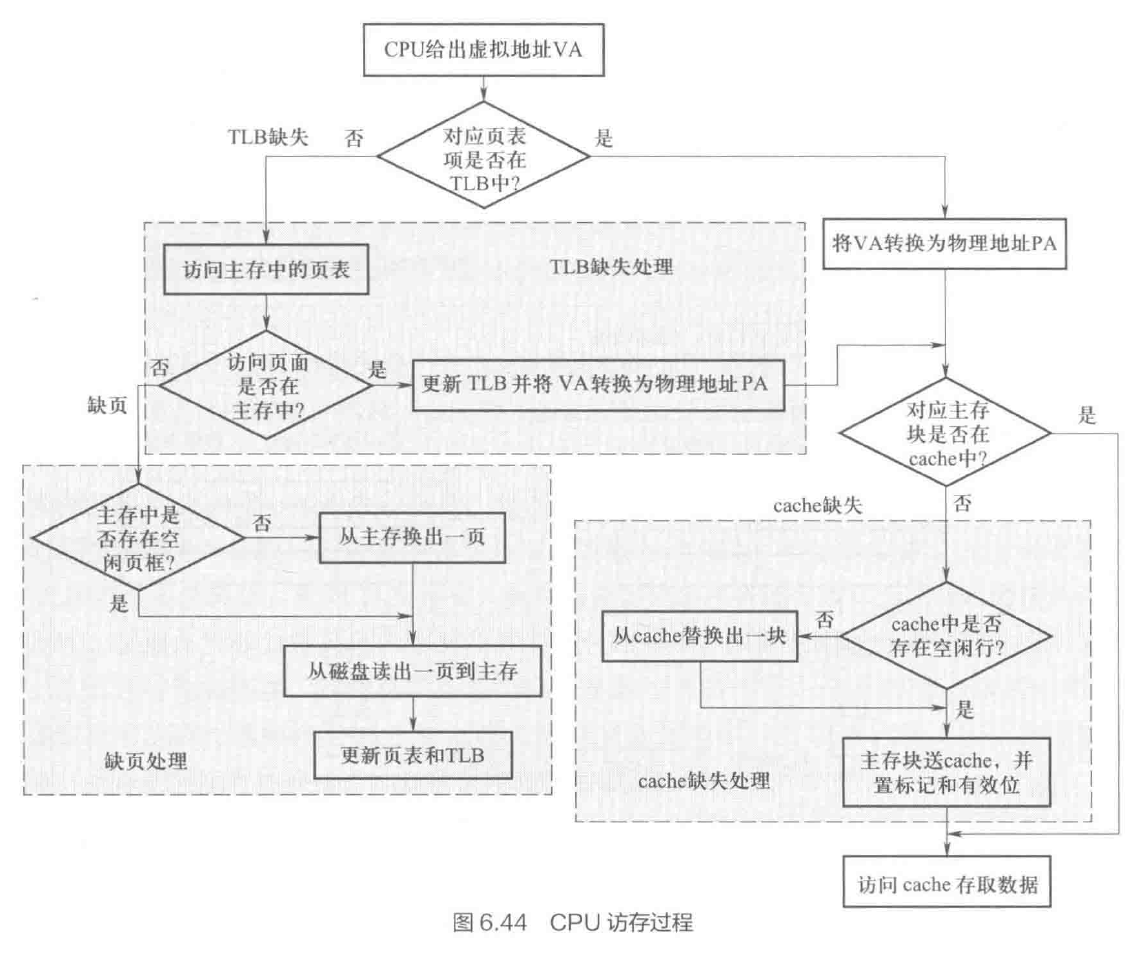
- 三种 miss 情况:TLB 缺失 → cache 缺失 → 缺页
- ❗ cache hit / miss rate 计算